Sampling from a multivariate Gaussian (Normal) distribution with Python code
2021-12-04Machine Learning Interview: Sampling and dataset generation
2022-01-17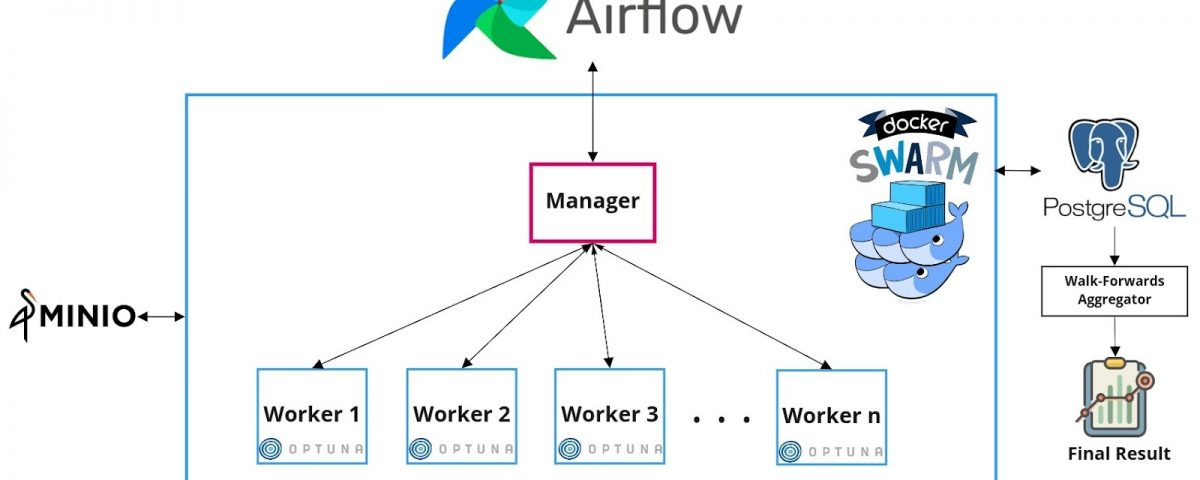
Table of Contents:
- Introduction
- Terminology
- Walk-forward Optimization
- Design of walk-forwards
- The Architecture
- Configuring cloud machines using Ansible
- Docker Swarm
- Optimization Engine
- Apache Airflow
- Shared Database Server (PostgreSQL)
- Shared Object Storage (MinIO)
- Walk-forwards Aggregator
- Conclusion
Introduction
In almost every trading system there are configurable parameters, e.g. indicator periods, directly affecting the system’s behavior and performance. These parameters are often decided by experts. For example, “Would it be better to use Exponential Moving Average (EMA) with a smoothing factor of 20 or a smoothing factor of 10?”. Optimization means running multiple trials using historical data with different sets of parameters aimed at finding optimal values of these parameters giving the highest profit or lowest volatility or some other desired goal. We need to assess the performance of the optimization process itself before using it for live trading. However, there is a big challenge! Parameter optimization is a very time-consuming task, due to the large search space. A single experiment can take days or weeks rather than minutes or hours. Fortunately, the increased prevalence of cloud computing provides easy access to distributed computing resources and scaling up parameter search to more machines. In this post, I will explain how we leveraged the parallel processing capability on a cloud infrastructure to cut down the runtime of the parameter optimization process. This post will give you an overview of the architecture. Each component has a lot of details that will be covered in future posts. This is a copy of the blog post I wrote at Eveince (formerly ParticleB).
Terminology
Before delving into details, let me define some terms that I will use throughout this post.
Backtest:
Process of applying a trading strategy to historical data to evaluate the performance of the strategy.
Walk-Forward Optimization:
Process of optimizing input parameters on a historical segment of data, then test forward in time on data following the optimization segment using the optimized parameters.
In-Sample (IS) Data:
The portion of historical data on which the parameters are optimized.
Out-Of-Sample (OOS) Data:
The portion of data that is reserved to actually evaluate the performance of a strategy with optimized parameters.
Objective Function:
A certain metric we are trying to maximize or minimize for a set of parameters.
Search Space:
The domain of all feasible parameters that can be drawn.
Optimization Sampling Algorithm:
An algorithm that determines how to draw a random sample (of parameters) from candidate samples at each trial.
Trial:
A single evaluation of the objective function during the optimization.
Optimization Experiment/Study:
A collection of trials that form a whole optimization task.
Walk-forward Optimization
Walk-Forward Optimization is a sequential optimization and backtesting applied to evaluate an investment strategy. It optimizes the parameter values on a past segment of market data (In-Sample (IS)), then it verifies the performance of the system by testing the optimized parameters forward in time on data following the optimization segment (Out-Of-Sample (OOS)). This process is then repeated by moving a window that progressively traverses the whole period of the data history with a pre-established step.
Since the process of finding the best parameters in a walk-forward is independent of other walk-forwards, the whole optimization can easily be scaled and parallelized by distributing and running walk-forwards on different machines. In such a setting, we need to exploit parallelism to find a good configuration in a reasonable time.
Design of walk-forwards
The design of a single walk-forward in the experiments is shown in Figure 1. Each walk-forward can be defined using four dates:
- optimization train start
- optimization train end
- optimization test end (backtest test start)
- backtest test end
During a single walk-forward optimization, a trading strategy is backtested several times (trials) with different sets of parameters on the optimization segment. Then the strategy is tested using the optimized parameters on the backtest segment (OOS). The main idea is that the parameter values chosen on the optimization segment will be well suited to the market conditions that immediately follow.
During the optimization with the in-sample data, we are looking for the “best” parameters. An objective function is a metric that we want to maximize or minimize in the optimizations. For instance, if the objective function is the overall profit, we will try to find the parameters that maximize the overall strategy profit during the in-sample period. In most cases, we might be more interested in maximizing risk-adjusted returns. Specifically, we use Sharpe Ratio, which is the most famous risk-adjusted metric, as the objective function in the studies.
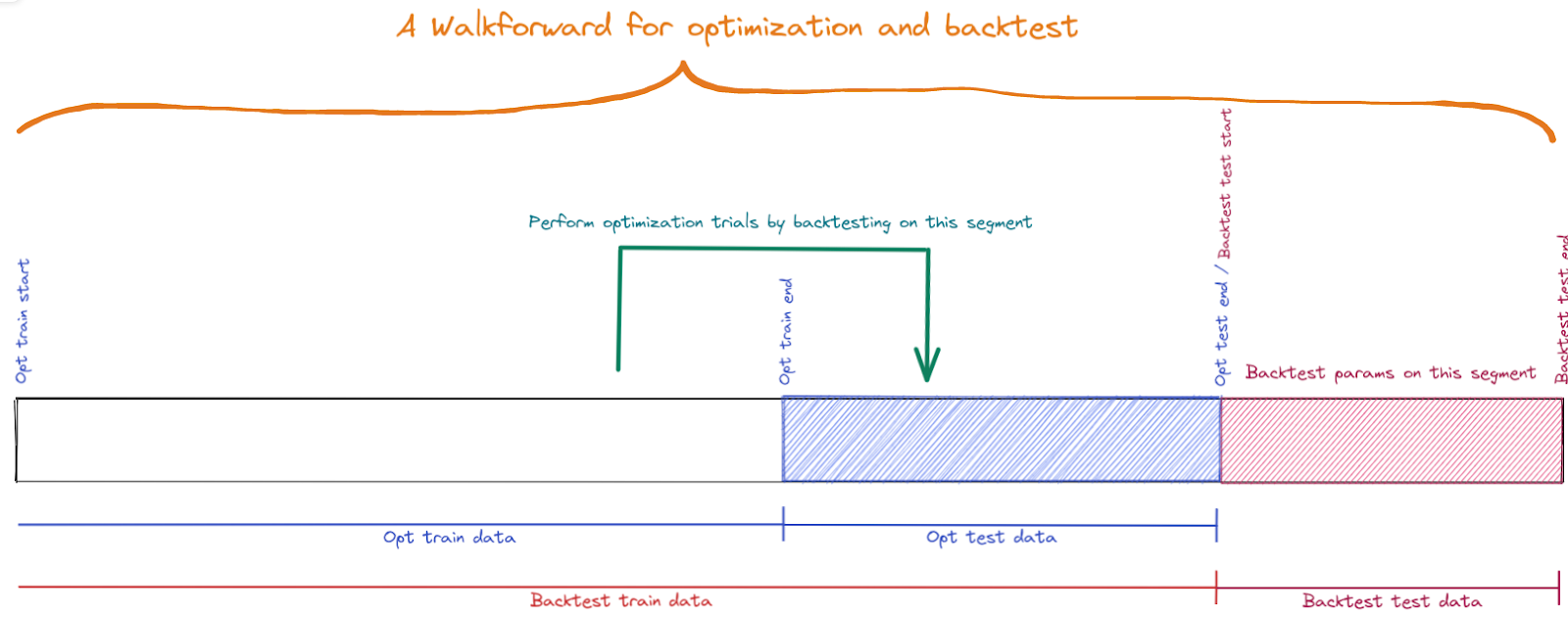
Figure 1. Design of a walk-forward
Concatenating backtest results of consecutive walk-forwards forms a whole backtest simulation of optimization results as shown in Figure 2. As you can see, we use an Anchored version of walk-forwards. That is, instead of having the in-sample periods “roll”, which means that only the latest window is used as in-sample, it uses all the previous windows as in-sample data.

Figure 2. A set of walk-forwards forming a whole backtest simulation
The Architecture
The general architecture of the cloud-based parameter optimization for a trading strategy is shown in Figure 3. Now let’s take a closer look at its components.
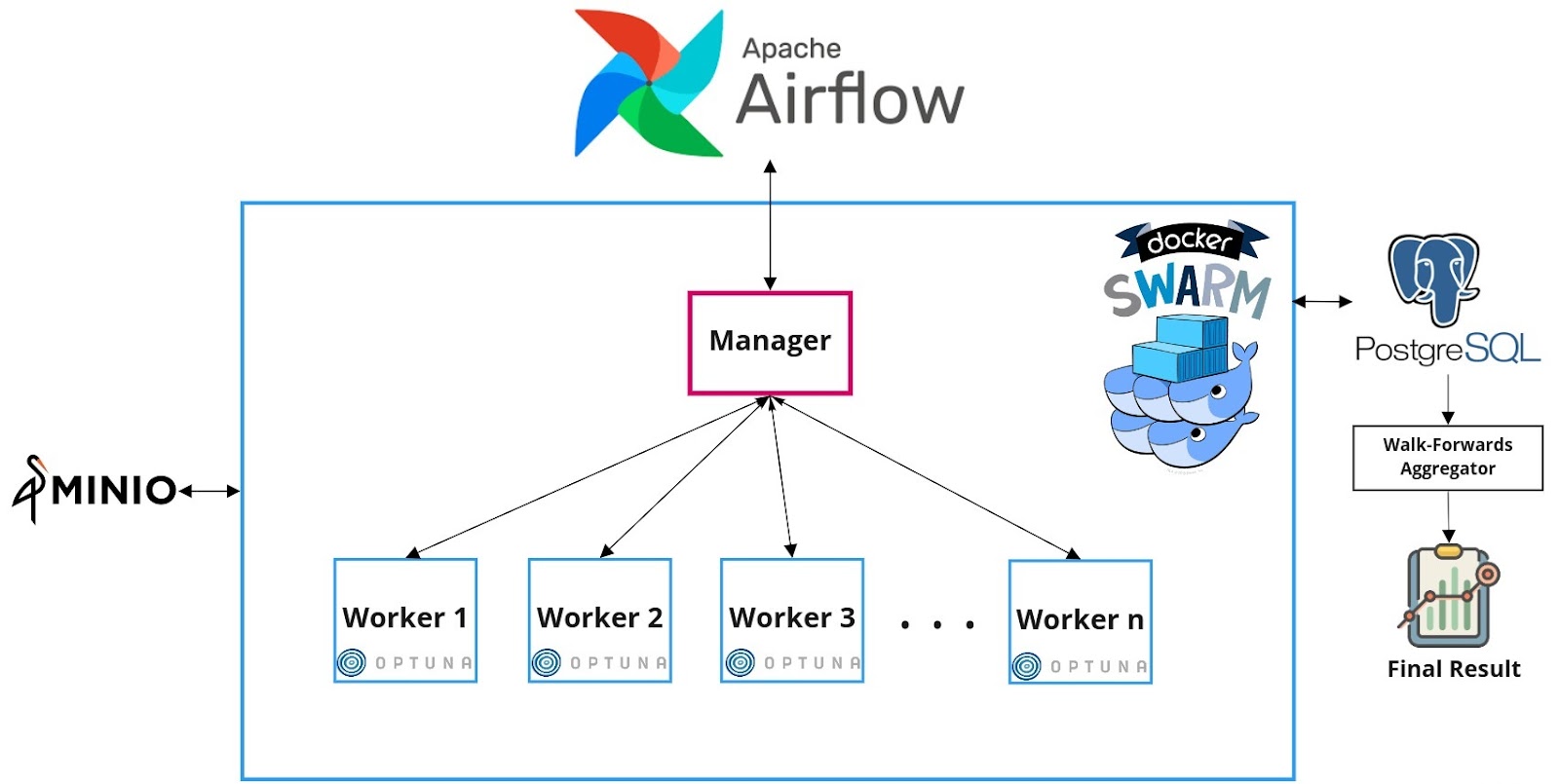
Figure 3. The architecture
Configuring cloud machines using Ansible
Before starting the optimization process, we need to configure the clean cloud machines and install requirements, e.g Docker, on them. Instead of individually configuring machines from the command line, we use Ansible to configure a large network of cloud machines in an automated way from one central machine. Specifically, we need to run an Ansible Playbook that executes the following tasks on machines listed in an Ansible Inventory:
- Install Docker
- Configure Docker Swarm Nodes
- Initialize Docker Swarm
- Join worker nodes to the Swarm
- Setup networks and firewalls
Docker Swarm
As shown in Figure 3, Docker Swarm is utilized to provide basic clustering capabilities, enabling multiple Docker Engines to be combined into a group to provide multi-container services. A Docker Swarm is a group of either physical or virtual machines that are running the Docker engine. In a swarm, there are typically several worker nodes and at least one manager node that is responsible for handling the worker nodes’ resources efficiently and ensuring that the cluster operates efficiently.
All codes have been dockerized and pushed to a Docker Container Registry to facilitate its deployment on cloud infrastructure. So each node needs to pull the docker image first. The developed docker container for walk-forwards provides a command-line interface that can be called with different arguments to perform optimization. These arguments are dates (defined in the “Design of a walk-forward” section) that specify the walk-forward. Therefore, performing a walk-forward optimization task can be viewed as running a command parameterized with specific dates. Once machines have been clustered together, Docker containers for different walk-forwards can be run on machines in the cluster.
Optimization Engine
The heart of the optimization process is based on the Bayesian Optimization Algorithm. Bayesian Optimization provides an efficient and effective strategy based on the Bayes Theorem to direct a search for global optimization of black-box functions. Using Bayesian Optimization, we can explore the parameter space more smartly, and thus reduce the number of backtests required to identify an optimal configuration for the strategy that allows us to be much more aggressive in the strategy construction process by considering larger parameter search spaces. We use Optuna to perform walk-forward optimization on each machine. Optuna is an open-source automatic hyperparameter tuning Python framework that has been widely used by the Kaggle community for the past 2 years. Optuna implements sampling algorithms such as Tree-Structured of Parzen Estimator (TPE), Gaussian Processes (GP), and Covariance Matrix Adaptation (CMA). Optuna allows optimizing functions in light environments as well as large-scale experiments in a parallel and distributed manner. It can be easily integrated with any of the machine learning and deep learning frameworks such as PyTorch, Tensorflow, Scikit-Learn, etc.
There are three main terminologies in Optuna:
- A Trial is a single evaluation of the objective function.
- A Study corresponds to a whole optimization task, i.e., a set of trials.
- An Objective Function to be maximized or minimized.
Shared Database Server
As shown in Figure 3, we use a shared PostgreSQL database server among all machines. Three types of data will be stored in this central database:
- Optuna internal states that are used during the optimization process. For more details about Optuna RDB storage visit RDBStorage.
- History of studies and trials for further exploration and analysis of optimization algorithm behavior.
- Final results of backtesting for each walk-forward.
Apache Airflow
We chose Apache Airflow 2 to schedule, orchestrate, and monitor the optimization workflow that is represented as a Directed Acyclic Graphs (DAG) of Tasks. The optimization DAG is responsible for performing the whole walk-forward optimization process. It consists of three tasks that are executed in order to run an optimization experiment (Figure 4).
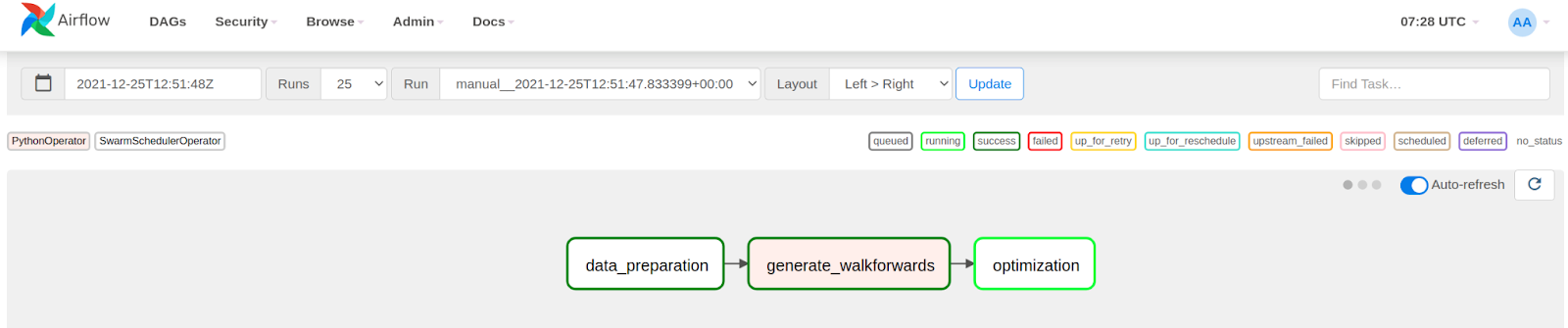
Figure 4. Walk-forward optimization DAG
- Data Preparation Task
This task fetches and then prepares required data that is shared among all cloud machines to run optimization and backtest for a walk-forward. This data includes candles, features, and labels. All these data will be uploaded to a MinIO bucket. MinIO is a high-performance and S3 compatible object storage built to store and retrieve any amount of data from anywhere.
- Walk-forward Generator Task
It is a simple PythonOperator task that generates a set of walk-forward optimization/backtest windows dates based on the start and end time of the backtesting simulation and the length of the optimization and test periods.
- Optimization Task
Here the main optimization process begins. This task gets the output of the previous task. This is done by a built-in feature of Airflow called XCom. XCom is the default mechanism of Airflow for passing data between tasks in a DAG. Then it creates a set of services (walk-forwards) on the Docker Swarm. This is where Airflow talks directly to the Docker Swarm. The manager node is responsible for scheduling and distributing these services on the swarm nodes. A service indicates that a Docker container needs to be started on a node in the Swarm cluster. At the same time, the manager node is also responsible for orchestrating containers and cluster management functions to maintain the state of the cluster. By default, the manager node also executes tasks as a worker node. Each worker node then receives the service created, scheduled, and assigned by the manager node, starts a Docker container to run the specified service. Workers constantly report the execution status of the assigned tasks to the manager node. Specifically, each worker node performs the following tasks, which corresponds to a walk-forward:
- Download required data from MinIO.
- Perform optimization on the optimization segment.
- Perform backtest using optimized parameters on the backtest segment.
- Store backtest results in the database.
We implemented a Custom Airflow Operator named SwarmSchedulerOperator to manage the Docker Swarm. Some responsibilities of this operator are as follows:
- Pulling a Docker image.
- Connecting to the Swarm Manager node.
- Creating swarm services.
- Removing and cleaning services from the Docker Swarm.
- Getting logs from docker swarm services and showing them in Airflow logs of DAG.
Walk-forwards Aggregator
The last step to get the final result of a whole backtest simulation is to aggregate the results of individual walk-forwards. It is simply done by concatenating the results of walk-forwards for different periods that have been stored in the shared database.
Conclusion
One of the determining tasks when building trading strategies is parameter selection. In this post, I have introduced the architecture we have employed at ParticleB that takes advantage of the computing power of the cloud to find parameters of a trading strategy. If you find this post useful, please share it with your friends and colleagues, and also do not hesitate to ask if you have any questions.